Introduction
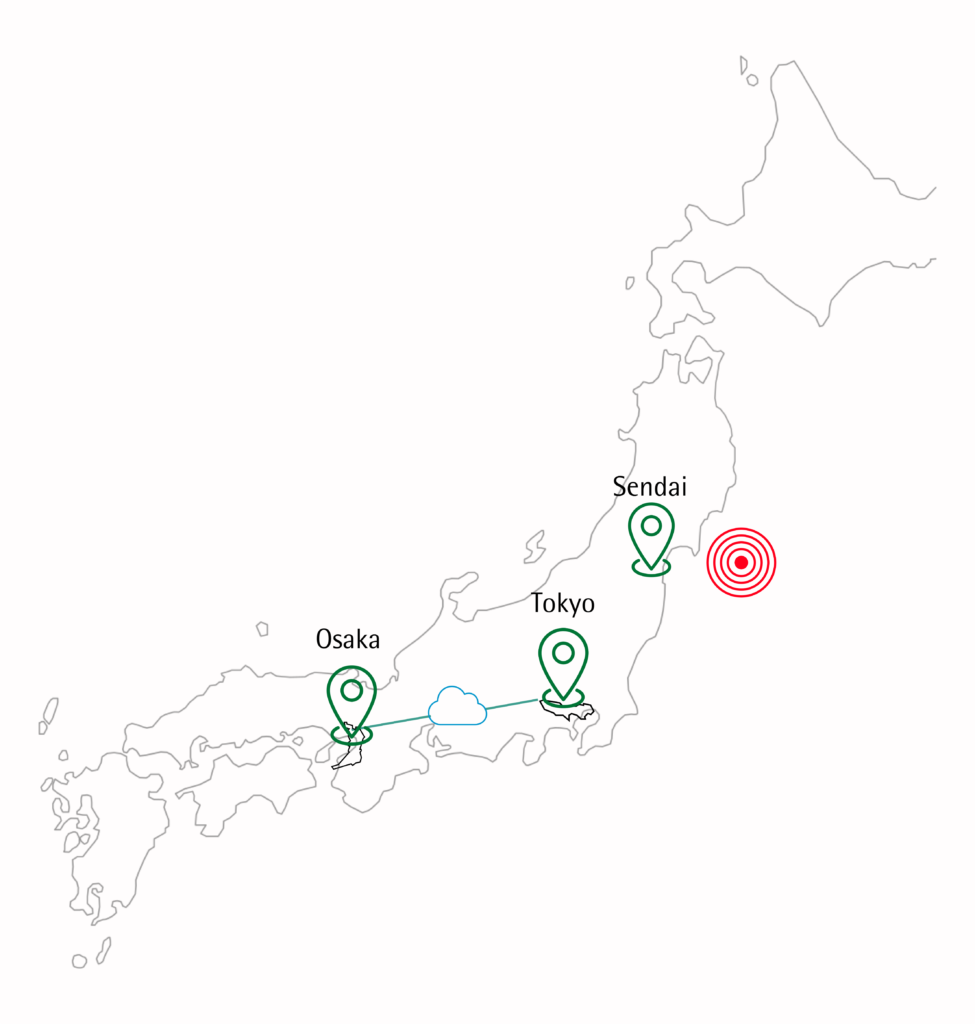
What happens if the machine, an AZ, or a region serving your customers fails? Nothing – if you rely on cloud-native deployments, stateless microservices, and multi-master databases. That’s the promise anyway. How many IT teams have the luxury of relying on multi-AZ deployments within a cloud? And what about geo-redundancy within a single Cloud? Only the vanguards have had the luxury to bake in such resiliency into their architectures. Our founding team was fortunate to have delivered such resiliency for one such vanguard in response to the 2011 Japan Tsunami. In fact, we had to fund significant innovations in the early distributed scale-out open-source and storage technologies to deliver Tsunami-resilient messaging serving 30M+ consumers in Japan. This inspired us to move the ball forward – how about insuring against the Big 3 clouds?
The butterfly effect(s) – on Clouds.
The following observations drove us to build multi-cloud resiliency –
- Happenings 1000+ miles away can have an outsized impact on your resiliency.
- Surprisingly, these happenings may impact your next-[rack, DC]door tenant before triggering your auto-scaling alarms.
- And you, as soon as you try to “auto-scale,” your cloud provider denies it. So long, cloud-native, Kubernetes-compliant, distributed scale-out architecture.
And while this is happening, the other cloud (literally) down the road has spare capacity at a discount that you can’t use. Or worse, you have an illusion of multi-cloud resiliency, except it takes 10x more time, effort, and $$s than your own primary cloud provider.
The proverbial N-copies of data .. across Clouds
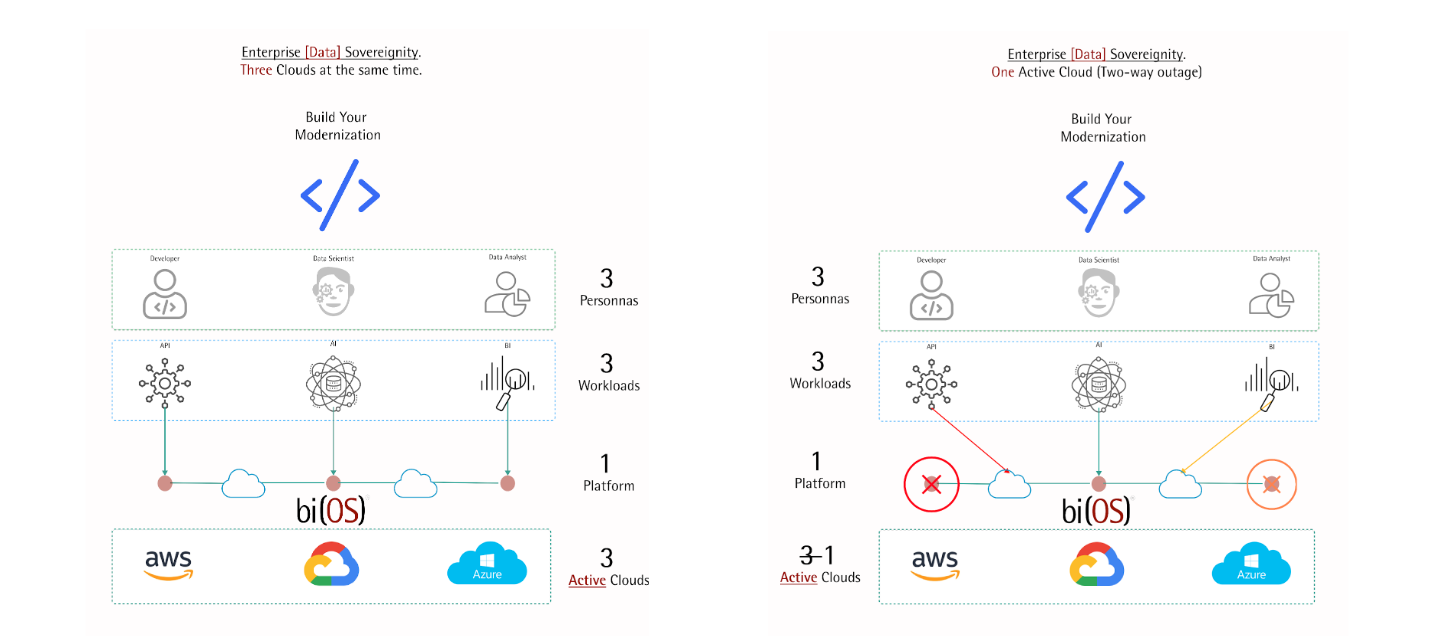
A key cloud innovation is N copies of data across instances, racks, and DCs. We asked why can’t the proverbial N copies of data be deployed across the Big 3? While distributed scale-out was in our DNA, we wanted to know the intricacies around “similar sounding” infrastructure across the Big 3. Hence we decided to run Dev, QA, and staging for bi(OS) across the Big 3 from Day-1. Over a few quarters we realized the subtleties of price-performance differences and how to tame them. This wasn’t easy. It mandated serving real-world application profiles (think p99 < 10ms), combining QoS and resiliency, and securing inter-cloud communication. Further, since the clouds make it hard on the customer’s purse to egress data, bi(OS) had to deliver a price-performance that was 10X+ better than alternatives.
And we are proud to announce – the sucker works! A single bi(OS) deployment can serve API, AI, and BI use-cases with QoS guarantees across the Big 3. Further, it is also resilient to any instance, rack, DC, or Cloud failure(s). And the benefits to customers are profound –
- If an entire cloud fails, applications hosted on their peer clouds continue without a blip
- The yin and yang of QoS and resiliency work together in a perfect harmony
- Multi-cloud resiliency is part of the architecture, not a bolt-on
Did we mention that it is 10X cheaper than your single-cloud MDS? We have done the math!
Conclusion
Pioneering distributed systems innovations should serve the customer’s needs and also satiate the engineering pride. This is one of our founding tenets, and our architecture of multi-cloud (data) sovereignty is a testament to that. This system will be showcased at the premier multi-cloud conference in a few weeks. Do join us to experience it for yourself and be amazed.
If you can’t wait, sign-up and go live in days!