Introduction
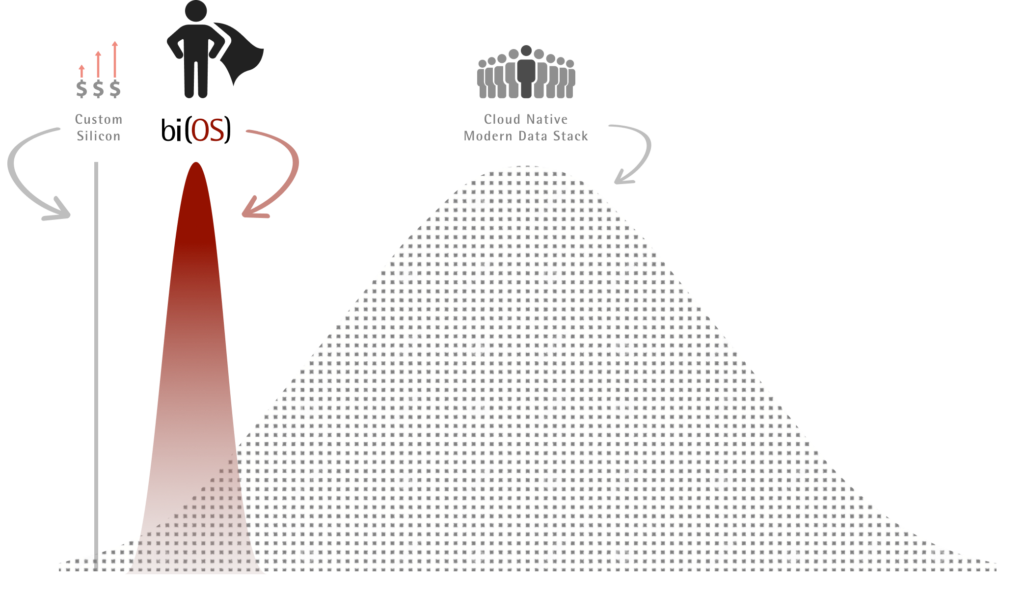
Since the birth of SQL in the mid 70’s, there has been a wall of separation between OLTP and OLAP use cases. One of the defining characteristics of this separation is the stringent need for speed and QoS (quality of service) by OLTP applications. Even today, Data Warehouses and Data Lakes pay lip service to speed and very little, if any, to QoS. Isima asked why can’t OLAP use cases demand the same (or even better) QoS than those mandated by the most stringent OLTP applications (e.g., Amazon Prime, Google Search)? And do so for a TCO of $0.004/sec on the public cloud.
Why care about QoS for OLAP use-cases?
Traditional OLAP systems served internal consumers via BI and Data Analysis tools. The rise of data producers, AI/ML capabilities, and elasticity of the Cloud nessaciated the Modern(?) Data Stack. This stack is attempting to help domains such as eCommerce, Cybersecurity, and Fintech. In this new age, the last mile of OLAP isn’t a BI report or the query run by a Data Analyst/Scientist. It’s an in-production ML model that recommends a product to a consumer, predicts fraud on a credit card swipe, or dynamically adapts the interest rate for an online loan application. And does so in milliseconds, predictably. Pioneers such as Google and Amazon realized this early on and invested heavily in QoS guarantees of these use cases1. Unfortunately, this requires a level of investment that only a select few can afford2. This fact was lost on the industry, while everyone jumped on the open-source, cloud-native, Modern(?) Data Stack.
bi(OS) – Built Different.
- Waiting to deliver a perfect recommendation through an ML model, possibly via running multi-armed bandits, isn’t possible or is exorbitantly expensive using the Modern(?) Data Stack. Most recommendation engines fall back to basics to meet the latency SLAs.
- Models that go awry during Black Friday, Big Bazaar sale events, forces business teams to turn off ML on those peak days, which account for upto 20%+ of yearly revenue (right when they are supposed to deliver value)
- The compute cost of rich feature inference in real-time is exorbitant, forcing engineering teams to dilute the model’s efficacy with simple heuristics.
bi(OS) solves for all these problems on the non-deterministic cloud. Today, we are releasing proof of these outcomes. Prior warning, its harsh detail won’t be friendly to the marketecture friendly crowd. So expect depth3. Before proceeding to results, let’s define QoS.
What is QoS?
QoS is the SLA (service-level-agreement) – usually measured as latency or throughput – that a consumer can expect. For customer experience, it is represented by the sustained performance of p50, p90, and p99 latencies over time, especially when the system is under duress (e.g., 70%+ utilization). We decided to measure bi(OS) for that scenario. So while Your Mileage May Vary; for the p99 of you, expect better results than what we are reporting. Now, how many benchmarks can claim that!
Results summary
Over a 12+hour run, bi(OS) sustained an average of 21.5K operations/sec with a 80 : 20 write : read ratio where every operation was a 1Kb insert or select. The table below provides summary and the accompanying post provides the details. The TCO of this system on GCP is $0.004/sec.
| Avg. over 12 hour period | insert | select |
| Throughput | 17,200 rows/sec | 4,300 rows/sec4 |
| p50 latency | 0.52 ms | 1.60 ms |
| p90 latency | 0.62 ms | 1.99 ms |
| p99 latency | 1.46 ms | 2.94 ms |
Conclusion
Lack of QoS inhibits the impact of last-mile ML/AI; the pioneers know this and have invested heavily to achieve non-linear outcomes. Such outcomes have been out of reach of all but a select few until today. Experience the outcomes that power Google, Amazon, and Hedge Funds for a $0.004/sec TCO. And bi(OS) doesn’t need an army or a village to make a use case live; a single Data Analyst can put a recommendation engine in production.
One more thing …

People in the industry ask us how can bi(OS) deliver such value while others can’t. One of the primary reasons is our diverse competence. Our founding team has built telco appliances that tsunamis can’t take down, Distributed scale-out databases that are SQL easy, and ML/AI applications that protect billions in revenue. This diversity allows us to imagine, design, and deliver non-linear solutions. And we are just getting started …
2. It’s a well known anecdote that Google builds it’s own SSDs.
3. Anyone who can find verified bugs in our reported findings will get a job offer with credible ESOPs at Isima.
4. We did 250 selects/sec where each select returned ~ 17 rows. But we didn’t batch inserts.