

Isima is the award winner for Next-Generation Unified Analytics. Isima stands out as the most visionary and forward-thinking unified analytics vendor. This is the wave of the future.
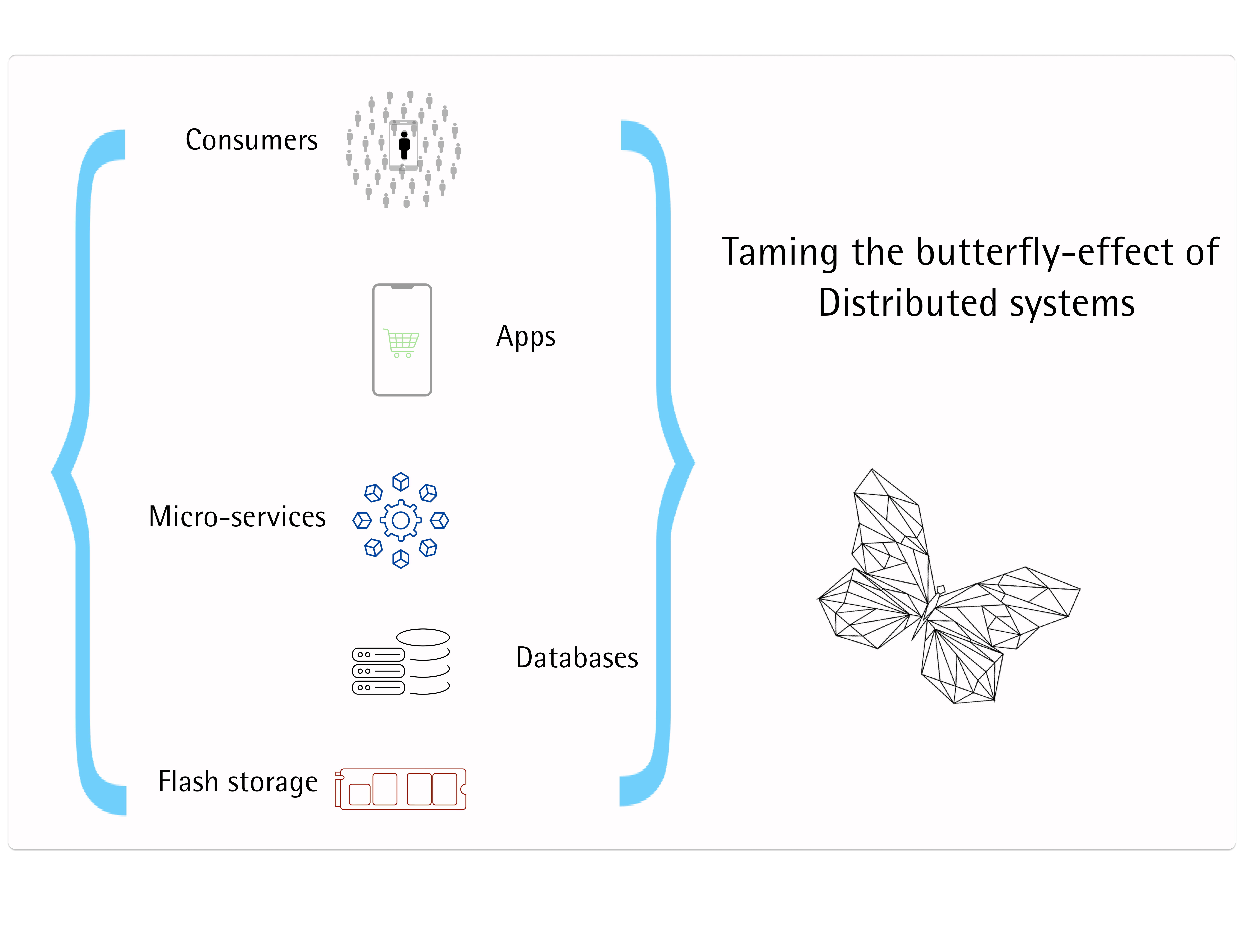
bi(OS)® shrinks the time for building and deploying models on real-time data from months to days. We were able to complete a churn reduction PoC in days for 5x the load.
Chapter Lead of ML & AI,
Tier-1 Telco
bi(OS)® allows us to become self-reliant to deliver data-driven impact. Data ideas which used to get curtailed due to lack of access to real-time data, can now be deployed to production in weeks.
Head of Analytics and Data Science
An eCommerce Unicorn
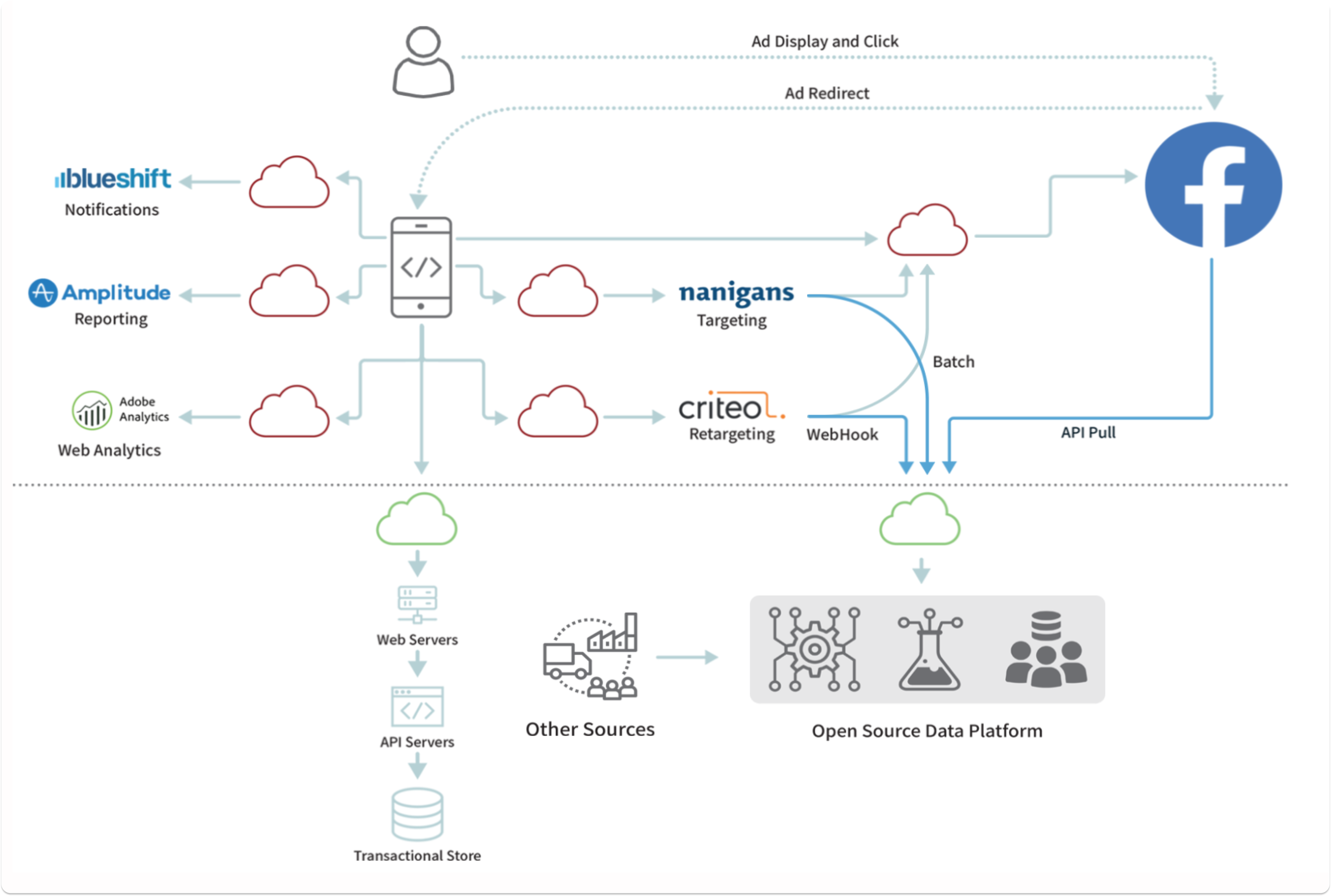
bi(OS)® is the only data platform to date that provides scale-out analytics with a simple conceptual framework. Define the ontology, features, alerts with a few clicks, and evolve your data app in hours.
Distinguished Engineer
Leading Network Equipment Provider
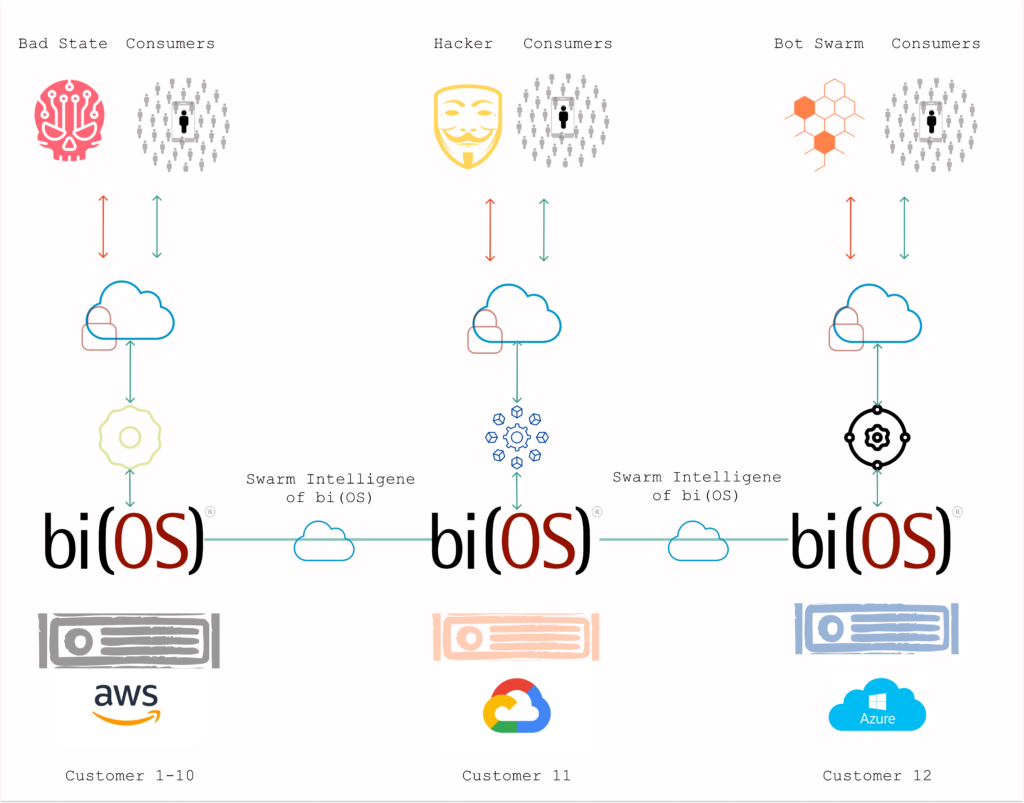
bi(OS)® is architected precisely as a real-time data platform should be. From ingest to insight and decisions, all aspects are taken care of within a simple and robust framework.
Sr. Director, Threat Intelligence
Market Leader in Fintech